Esta semana, continuamos echando un vistazo a los principios fundamentales de las redes neuronales y el campo del Aprendizaje Profundo. Si la semana pasada hablábamos de los primeros pasos de la industria, y los conceptos principales de las redes neuronales convencionales, hoy echamos un vistazo al siguiente paso lógico del sector, con las redes convolucionales.
Durante esos años “vacíos” entre el desarrollo de las primeras redes neuronales y el momento en que las condiciones (disponibilidad de datos, mejor hardware) fueron suficientes para dar entrada al actual boom de la IA, la industria por supuesto no estuvo de brazos cruzados: es en esta época en la que el trabajo se centra en el desarrollo de sistemas expertos, adecuados para la resolución de problemas muy concretos. Una de las herramientas más interesantes para el campo de la IA que surgen en esta época son las redes Convolucionales, responsables de un importante salto en el análisis de imágenes.
Para entender el funcionamiento de esta técnica, primero hay que considerar qué es una imagen –o al menos, como la entienden los ordenadores. Resumiendo, hablamos de una matriz (es decir, una colección ordenada de números), cada elemento describiendo que aspecto tiene un punto concreto (i.e. un píxel). En blanco y negro, se trata de un único valor: cuanto más cercano a 0, más oscuro el punto, y cuanto mayor, más se acercará al blanco. En el caso de las imágenes a color, es un poco más complicado: cada pixel constará de 3 valores, normalmente representando la proporción de rojo, verde y azul que compone el color de ese punto concreto (aunque hay otras formas de representar la “mezcla”).
De esta forma, podemos representar cualquier imagen como un conjunto de puntos, esos sí, con una diferencia importante respecto de otros conjuntos numéricos (como los que serían los datos de entrada de una red neuronal convencional): la posición relativa de cada pixel. Esto es, dado un determinado punto, considerar no solo la información contenida en ese punto, si no también los que le rodean, la posición que ocupa en la imagen, etc. ¿Cómo podemos entonces tener en cuenta este contexto posicional a la hora de analizar imágenes usando redes neuronales?
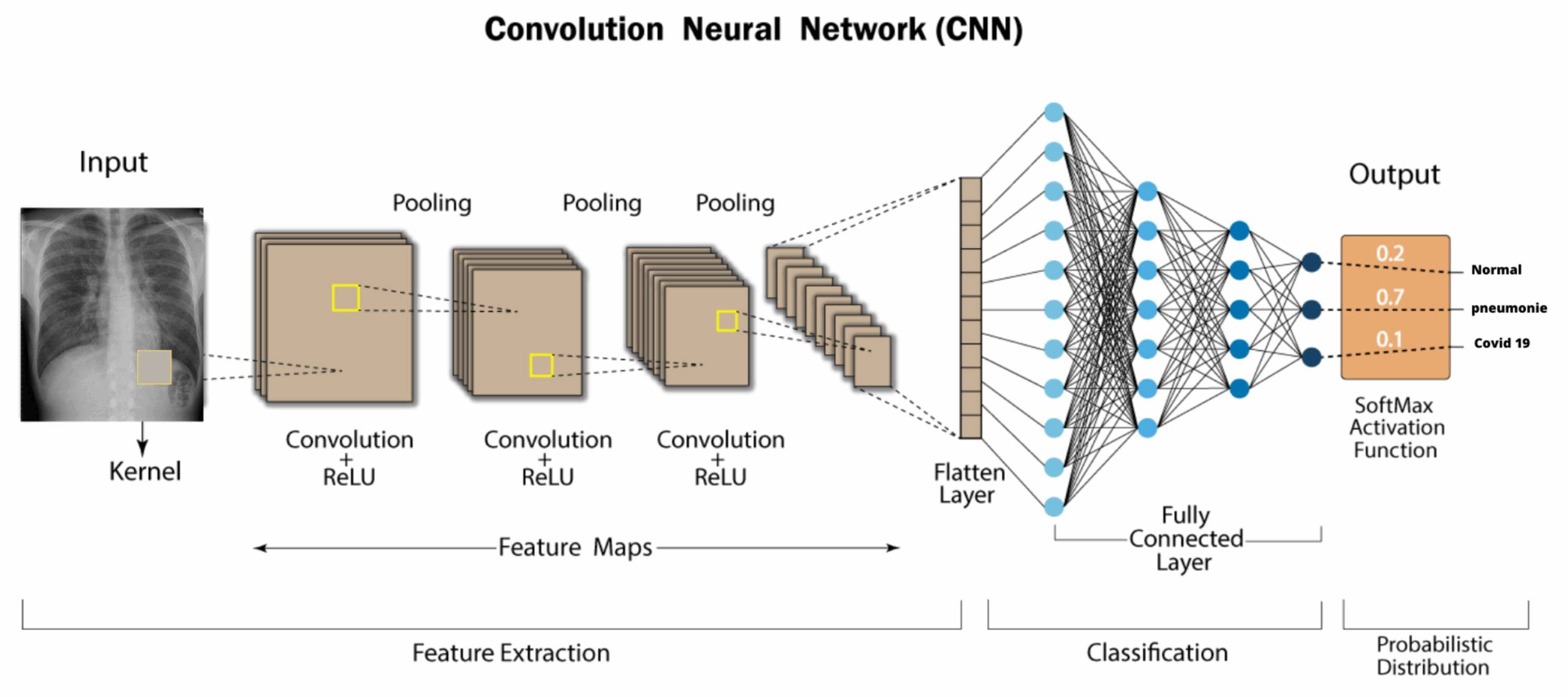
Ahí es donde entran en juego las Redes Neuronales Convolucionales. Una red neuronal lineal (de las que hablamos la semana pasada) funciona absorbiendo como datos de entrada todas las características de un determinado elemento, y haciendo que pasen por todas las neuronas de la capa, que constituyen el principal elemento funcional de la red. Las Redes Neuronales Convolucionales, en contraste, dividen la imagen de entrada en multitud de fragmentos pequeños, y aplican sobre ellos elementos llamados filtros. Así, por ejemplo, para analizar una imagen de 256 píxeles de alto por 256 de ancho, iríamos cogiendo pequeños cuadrados de 3×3 píxeles, operando sobre ellos con un filtro –que podemos visualizar como una matriz del mismo tamaño, en este caso 3×3–, y obteniendo de cada operación un resultado. Todos estos resultados, colocados en cuadrícula resultarán en una nueva imagen, preparada para pasar por un nuevo filtro:
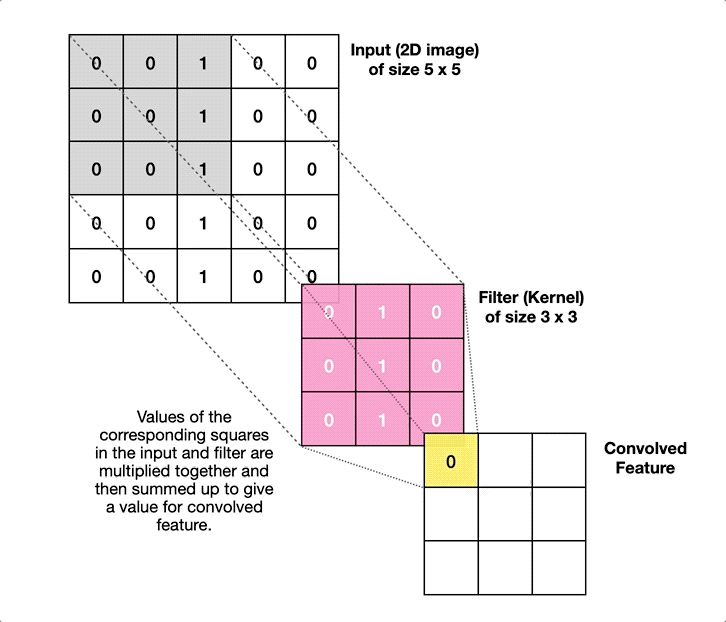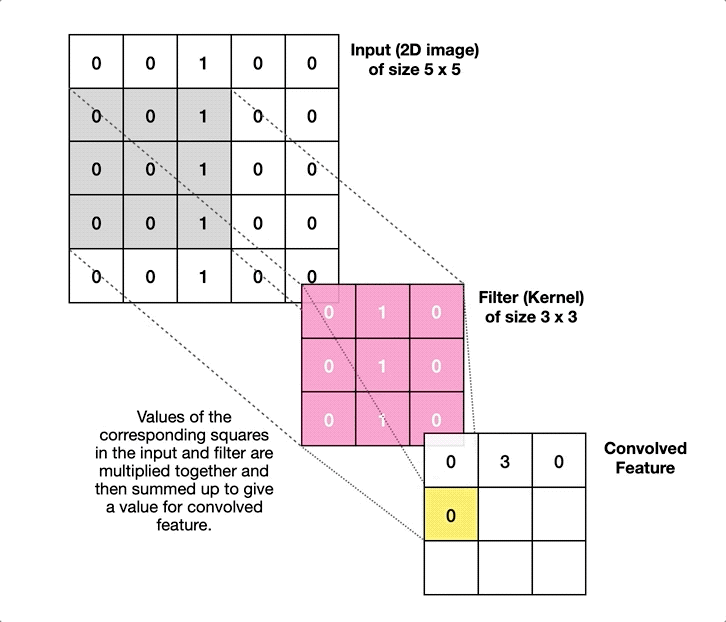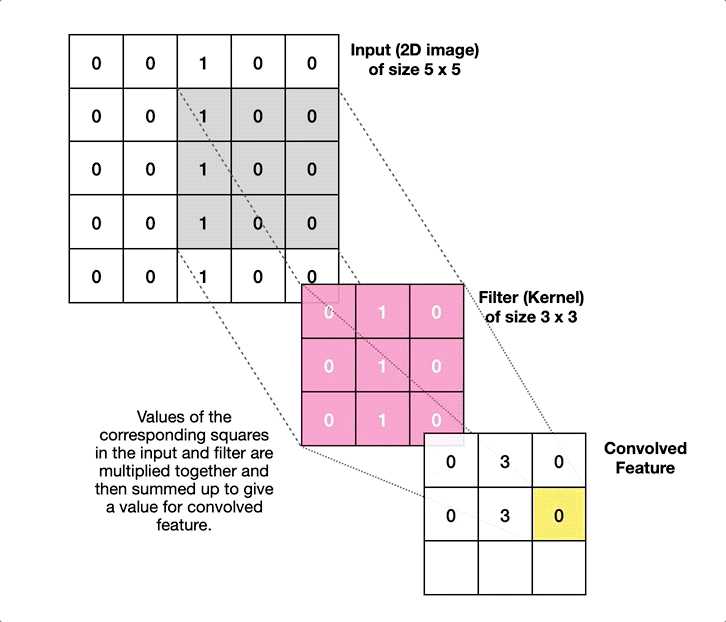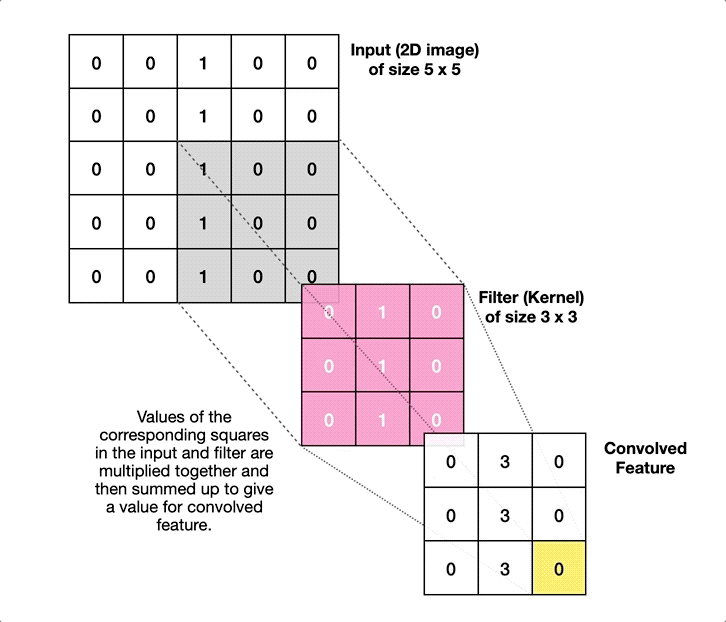
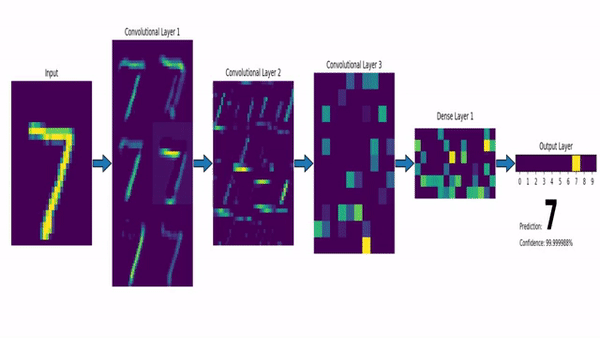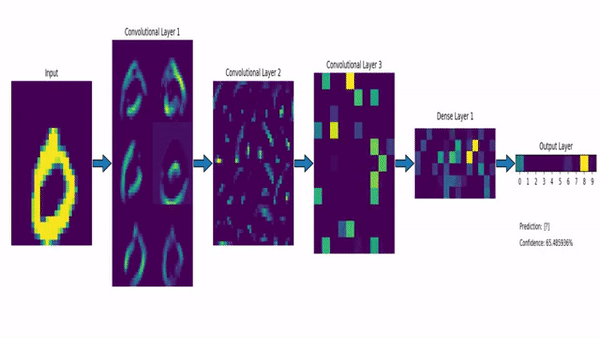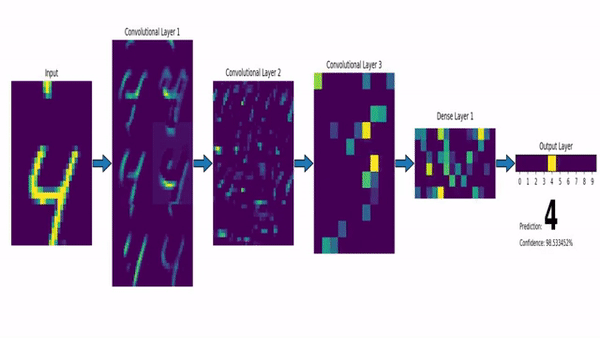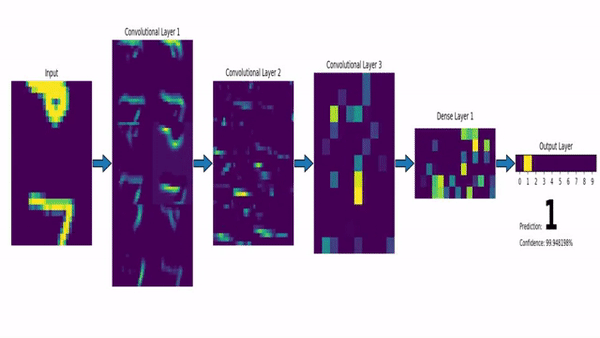
Como se ve en la imagen anterior, esto permite utilizar filtros específicos para detectar bordes, zonas de mayor contraste, etc (algo que ya se hacía antes del advenimiento de las redes neuronales), aunque hoy por hoy lo más habitual es usar capas convolucionales como parte de un sistema de aprendizaje máquina. Es decir, los filtros se van actualizando como si fueran perceptrones, usando el mismo proceso de retropropagación que mencionamos en el artículo de la semana pasada. De hecho, lo habitual es combinar ambos tipos de elementos, con una primera tanda de filtros que reducen la imagen a una colección de números, codificando su posición, relación con pixeles cercanos, etc; seguida de una serie de capas densas de neuronas, que se encargan de la última fase del aprendizaje, realizando las labores de análisis, clasificación, etc, que nos proporcionan el resultado final.
Por supuesto, las Redes Neuronales Convolucionales son solo una más de las muchas herramientas disponibles a la hora de configurar un sistema de Aprendizaje Profundo, pero son bastante relevantes en cuanto a su utilidad en multitud de campos dependientes del análisis de imagen. Más allá de utilidades tan mundanas como la digitalización de texto, reconocimiento facial o análisis de tráfico en tiempo real, también ha encontrado una aplicación extensa en el campo de la medicina: tanto a nivel investigativo, donde puede ayudar a analizar patrones y características de las distintas poblaciones de muestra, o incluso intuir nuevas propiedades en farmacología; como en el sector del diagnóstico médico, donde estas redes neuronales ya forman parte de las herramientas utilizadas para el análisis de TACs, radiografías, y otras técnicas de imagen médica.
Con esto terminamos esta sección sobre los distintos bloques que componen la actual tecnología de Redes Neuronales y Aprendizaje profundo. La semana que viene, examinaremos las redes neuronales recurrentes, y la pieza clave que ha permitido el actual auge de los grandes modelos de lenguaje: los transformers.
