La Inteligencia Artificial es el tema de moda, de eso no hay ninguna duda. Se trata de una tecnología pionera, que está abriendo nuevas oportunidades de investigación, industria y negocio, que ha revolucionado la manera en la que se entienden tecnologías más tradicionales como la ciencia de datos o el análisis de imagen, y que en definitiva ha alcanzado un nivel de penetración en el imaginario colectivo que hace imposible ignorarla. Este mismo blog ya ha centrado bastantes de sus entradas en la IA, al fin y al cabo.
Sin embargo, se trata también de una tecnología (o más correctamente, un conjunto de tecnologías) que se ve lastrada por unas expectativas poco realistas, una incomprensión generalizada de unos conceptos no muy fáciles de entender, y un omnipresente interés de mercado por parte de empresas tecnológicas, fabricantes de GPUs, etc.
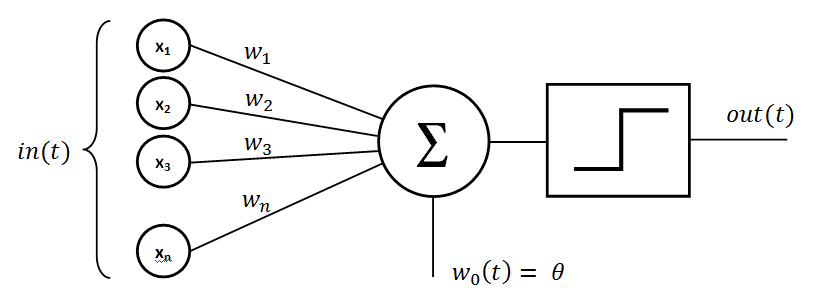
El concepto de Inteligencia Artificial, es decir, la capacidad de los sistemas informáticos para realizar tareas normalmente adscritas a la inteligencia humana, es prácticamente tan antiguo como los mismo ordenadores; su evolución más reciente, la que llena titulares y alimenta las herramientas de análisis o de generación de texto, se basa fundamentalmente en lo que conocemos como Aprendizaje Máquina, y más concretamente, en el Aprendizaje Profundo y las redes neuronales. Por tanto, vamos a centrarnos en explicar este último concepto, y la manera en la que ha ido desarrollándose en los últimos años.
Una red neuronal es, como cabría esperar, una colección de neuronas conectadas entre sí, formando una red. No se trata, sin embargo, de una neurona en el sentido biológico del término –aunque en este caso la naturaleza sirviese de inspiración para el modelo tecnológico; a lo que llamamos neurona es a lo que formalmente se denomina perceptrón, una unidad mínima de computación, en el que entran uno o más números, opera sobre ellos en base a un valor dado (al que llamamos peso), y nos devuelve una salida, otro número.
Por si mismo, una única neurona no hace mucho, aunque puede ser muy útil en casos particularmente sencillos en los que entran en juego pocas variables; sin embargo, conectando una gran cantidad de perceptrones en paralelo, operando al mismo tiempo sobre gran cantidad de entradas, ya obtenemos una red neuronal, con mucha mayor potencia de cálculo. Si además agrupamos varias de estas capas, de forma que la salida el primer conjunto de neuronas (el resultado de todas esas operaciones realizadas en paralelo) sirva como entrada para las capas posteriores, obtenemos una red neuronal profunda – es de esta arquitectura de donde obtenemos el nombre de Aprendizaje Profundo.
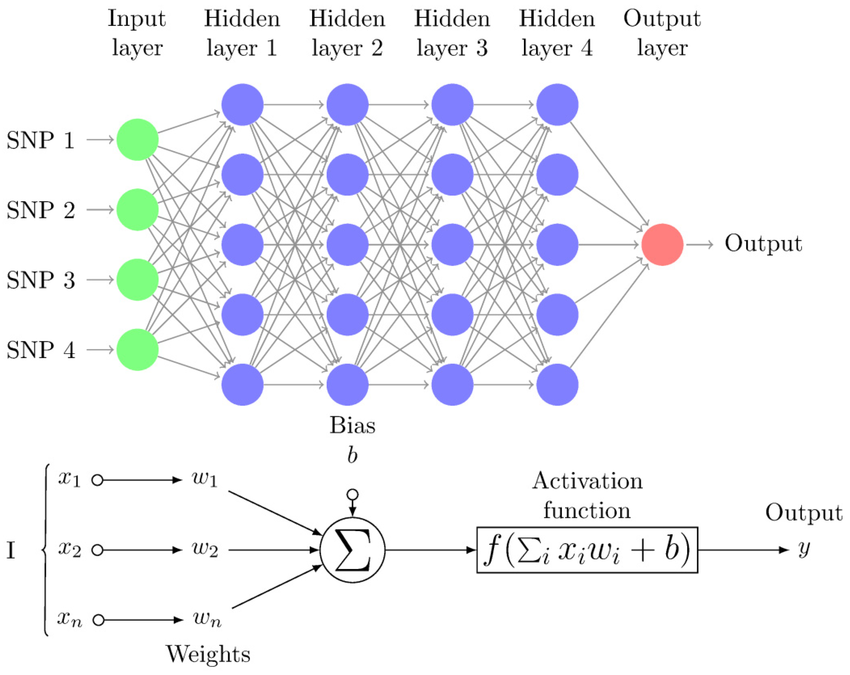
Así, dado un conjunto de datos sobre un elemento concreto, las neuronas van operando sobre cada uno de ellos, de forma consecutiva, hasta tener un dato final, correspondiente a algún parámetro que queramos conocer. Si tomamos, por ejemplo, el caso de una vivienda, podríamos pasarle a nuestra red neuronal distintos datos sobre el inmueble (localización, tamaño, infraestructura, fecha de construcción…) y obtener de vuelta su precio de venta estimado.
Pero la verdadera potencia del Aprendizaje Profundo viene precisamente de la primera parte del nombre, de la capacidad de la red para aprender de forma relativamente autónoma. Esos pesos de los que hablábamos antes, particulares para cada neurona, pueden ser modificados para ajustar la función a nuestro objetivo: alterando los suficientes pesos, las suficientes veces, probando cada vez ligeras variaciones, podemos llegar a afinar los suficiente nuestra red como para llegar al objetivo deseado. Esto es lo que se denomina Retropropagación: teniendo un conjunto de entradas, con una salida conocida, podemos ir modificando los pesos de las neuronas, desde la última a la primera, para acercar su funcionamiento al ideal. Con un conjunto de entradas y salidas conocidas lo suficientemente grande, se puede adaptar una red neuronal para ser capaz de interpretar una gran variedad de datos de entrada posible. Esta es la quintaesencia del Aprendizaje Profundo, y se realiza de forma automática sobre grandes conjuntos de datos.
Nada de esto es una tecnología nueva, como tal: la idea de una red artificial de neuronas puede encontrarse en trabajos de los años 40, y el primer perceptrón simulado con éxito se desarrolló a finales de los 50. Sin embargo, y aunque hubo discretos avances teóricos durante los 60 y 70, no ha sido hasta principios del siglo XXI que el aprendizaje máquina ha conseguido avanzar a pasos de gigante. Los responsables: la mayor capacidad de computación del hardware disponible; los avances realizados en distintas áreas de las ciencias informáticas, que permitieron confrontar viejos problemas con nuevas perspectivas; y, gracias a varias décadas de una digitalización cada vez mayor, la capacidad de acceder de grandes conjuntos de datos con los que entrenar las redes neuronales.
Con esto solo hemos visto, muy por encima, los principios fundamentales que dieron comienzo al campo del Aprendizaje Profundo, pero aún queda bastante por contar, incluso a modo de vistazo general. La semana que viene continuaremos, adentrándonos en algunas de las herramientas de análisis que han permitido extender el uso de las redes neuronales a campos como el análisis de imágenes.
